GDPR-säker AI-sökning för offentlig information
Ett verkligt experiment i att förenkla komplex reglering med EU-baserad inferens
Introduktion: när information finns men användbarhet misslyckas
Inom många områden är information inte knapp — den är fragmenterad.
Offentliga regleringar, riktlinjer och instruktioner finns ofta över flera källor, var och en auktoritativ isolerat. Kommunala webbplatser, branschportaler och officiella dokument innehåller all korrekt information, men användare kämpar ändå för att hitta tydliga svar.
Denna artikel beskriver ett verkligt experiment i att förenkla åtkomst till komplex reglerande information med hjälp av retrieval-augmented generation (RAG) och privat EU-baserad AI-inferens. Fokus är inte på att ersätta befintliga auktoriteter, utan på att möjliggöra nationell åtkomst i ett landskap dominerat av lokalt och institutionellt ägande.
Varför inferensens plats spelar roll före allt annat
Innan vi diskuterar användningsfall, arkitektur eller SEO, måste en begränsning adresseras: var AI-inferens körs.
Offentligt riktade applikationer som hanterar regleringar, medborgarinformation eller medborgarvägledning måste operera inom tydliga datagränser. Även när själva datan är offentlig, så är användarfrågor och interaktionsmönster det inte.
Det kravet ledde till skapandet av Juicefactory.ai — ett privat AI-inferenslager som opererar helt inom EU. Dess omfattning är avsiktligt begränsad:
- endast inferens
- ingen lagring av persondata
- kunddata används inte för träning
- OpenAI-kompatibla gränssnitt för enkel integration
Juicefactory är inte positionerat som en applikationsplattform, utan som infrastruktur: en kontrollerbar runtime för AI-inferens där efterlevnad är explicit snarare än antagen.
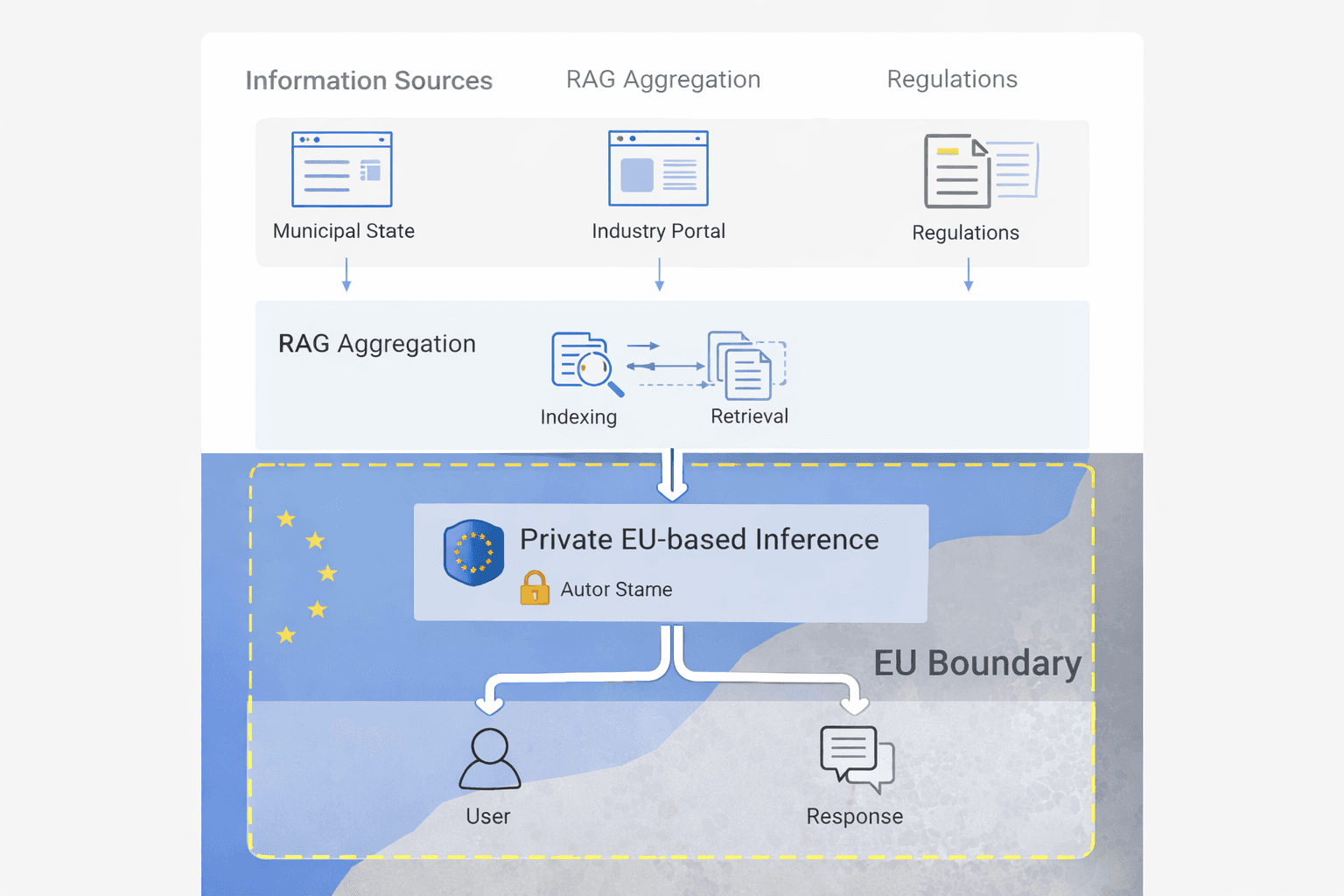
 Arkitektur som visar hur offentliga informationskällor flödar genom RAG-aggregering in i privat EU-baserad inferens, och bibehåller tydliga datagränser.
Arkitektur som visar hur offentliga informationskällor flödar genom RAG-aggregering in i privat EU-baserad inferens, och bibehåller tydliga datagränser.
Fallstudie: Sopinfo.se — förenkla ett nationellt fragmenterat problem
Sopinfo.se är inte en traditionell produkt eller kommersiell tjänst. Det är ett experiment.
I Sverige är ansvaret för avfallshantering och återvinningsinformation högst decentraliserat. Kommuner publicerar sina egna regler och vägledning. Branschpartners underhåller separata portaler — som sopor.nu — som innehåller korrekt information men inte alltid är lätta att navigera.
Resultatet är ett klassiskt användbarhetsgap:
- informationen finns
- den är ofta korrekt
- men den kräver många klick, lokal kunskap eller tidigare kontext för att nås
Sopinfo.se skapades för att utforska om denna fragmentering kunde förenklas på nationell nivå, utan att försöka ersätta lokal auktoritet eller institutionellt ägande.
Målet är att hjälpa medborgare förstå vad som gäller för dem, snabbare.
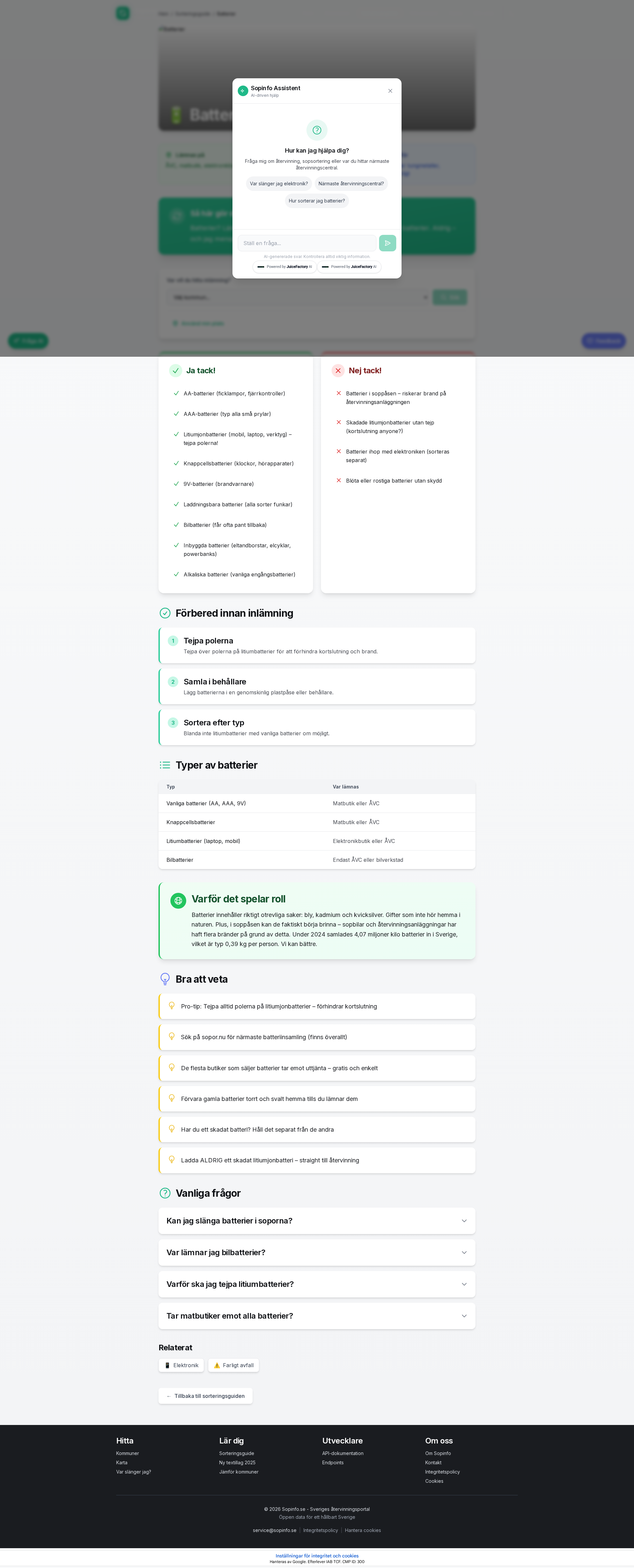 Verklig skärmdump som visar Sopinfo.se AI-chatt som svarar på en fråga om batteriåtervinning i Stockholm, med källhänvisning.
Verklig skärmdump som visar Sopinfo.se AI-chatt som svarar på en fråga om batteriåtervinning i Stockholm, med källhänvisning.
Ett experiment i nationell användbarhet, inte lokal auktoritet
Detta tillvägagångssätt går medvetet in i ett rött hav (läs mer om min strategi för röda oceaner).
Lokal auktoritet finns redan. Kommuner och branschorganisationer äger datan. Att konkurrera med dem på lokal fullständighet skulle vara ineffektivt och onödigt.
Istället fokuserar experimentet på:
- nationell upptäckbarhet
- förenklade åtkomstvägar
- användarintention snarare än dokumentstruktur
Hypotesen är att det finns utrymme för ett kompletterande lager: ett som hjälper användare navigera mellan auktoriteter snarare än inom en enskild.
Det här handlar inte om att rankas över kommuner. Det handlar om att hjälpa användare nå dem.
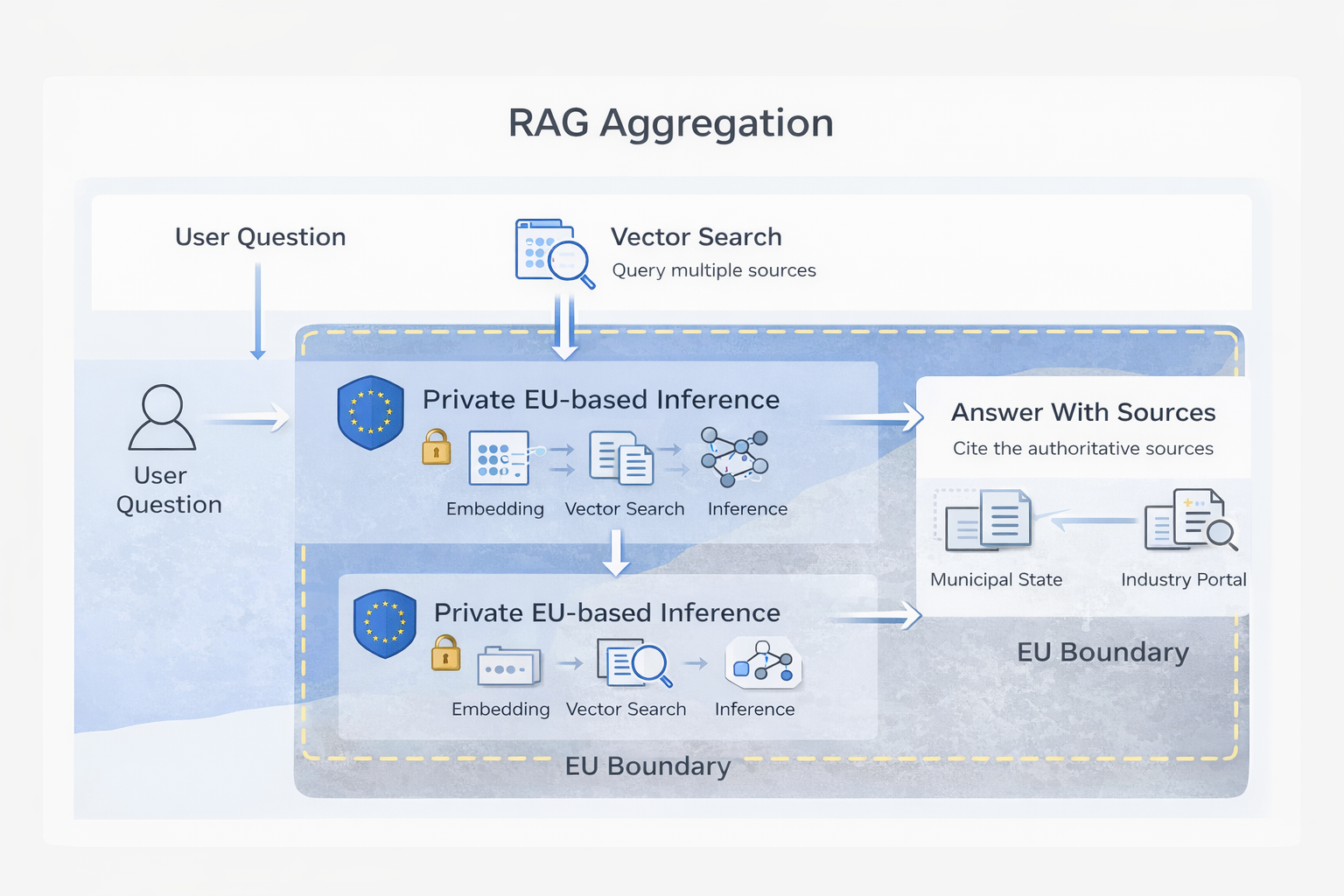
Teknisk arkitektur: RAG som ett aggregeringslager
Den tekniska uppsättningen reflekterar denna filosofi.
Kärnkomponenter
- Qdrant används för att lagra och indexera innehåll från flera källor
- Information bäddas in med Qwen3 4B embeddings
- Användarfrågor och svarssyntes hanteras av Qwen3 30B VL
- All inferens körs på privat EU-baserad infrastruktur, tillhandahållen av Juicefactory.ai
Systemet uppfinner inte regler. Det hämtar, kontextualiserar och pekar användare till rätt auktoritativ källa.
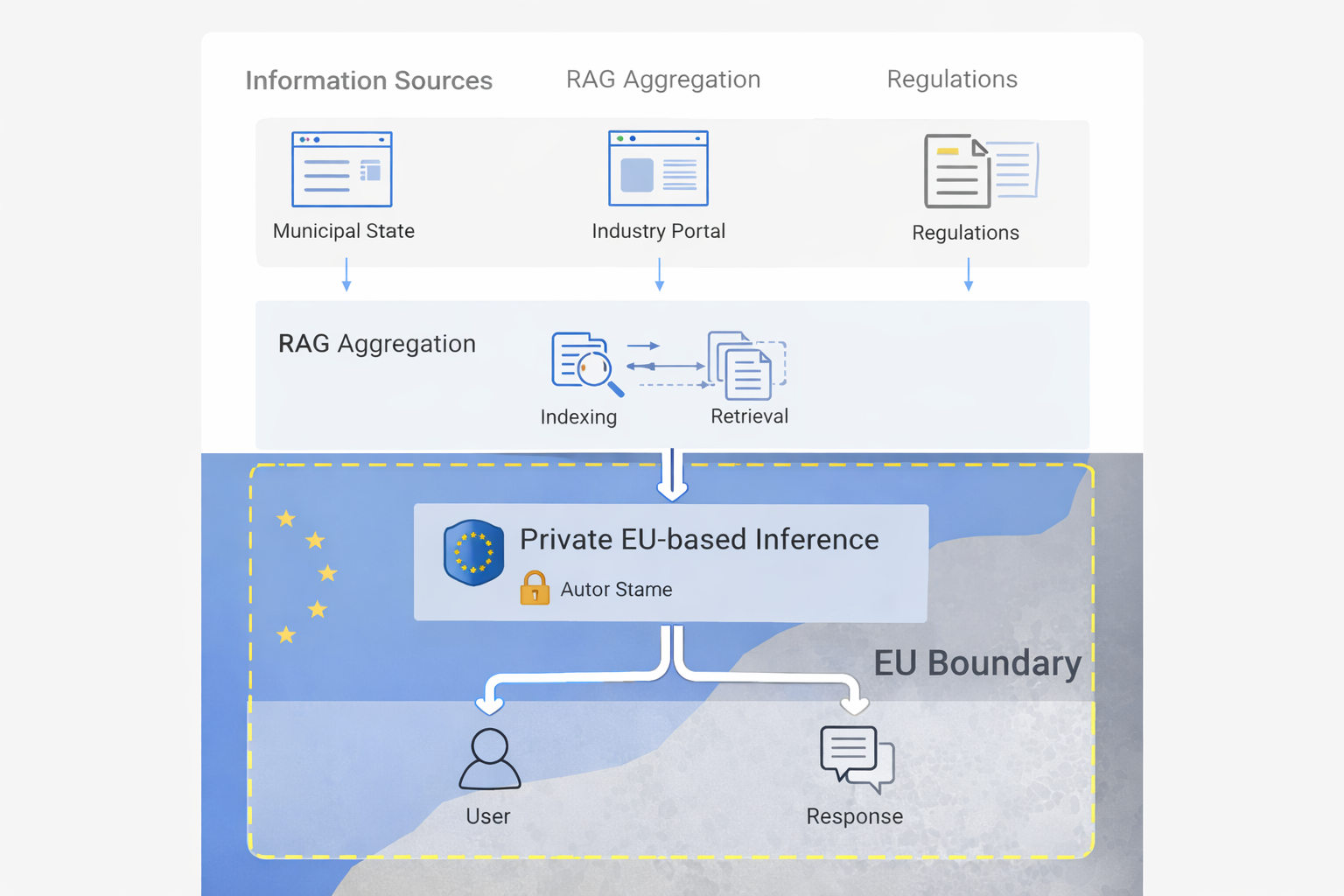
 Tekniskt flöde som visar hur användarfrågor processas genom vektorsökning, privat EU-baserad inferens och returneras med källhänvisning.
Tekniskt flöde som visar hur användarfrågor processas genom vektorsökning, privat EU-baserad inferens och returneras med källhänvisning.
SEO som en bieffekt, inte det primära målet
Även om Sopinfo.se är ett experiment i användbarhet, ger det också en möjlighet att utforska SEO i konkurrensutsatta, auktoritetstäta domäner.
Genom att:
- svara på riktiga användarfrågor
- länka tillbaka till auktoritativa källor
- observera frågemönster
framträder systemet naturligt long-tail informationsbehov som är underutnyttjade på nationell nivå.
Det här är inte ett försök att manipulera sökmotorer. Det är en utforskning av hur intentionsdriven åtkomst kan samexistera med befintliga auktoritetsstrukturer.
Varför privat EU-baserad inferens är nödvändig här
Även om mycket av informationen är offentlig, så är inte interaktionslagret det.
Användarfrågor, beteendemönster och kontextuella frågor kräver tydliga hanteringsgränser. Att använda privat, EU-baserad inferens säkerställer:
- regelverksklarhet
- förutsägbar datahantering
- transparens för offentligt riktad experimentering
Detta gör det möjligt att genomföra sådana experiment ansvarsfullt, utan att introducera dolda beroenden eller ogenomskinliga dataflöden.
Avslutande tankar
Sopinfo.se är inte positionerat som en färdig lösning. Det är ett kontrollerat experiment.
Dess syfte är att testa om AI, när den kombineras med retrieval och privat inferens, kan göra komplex, decentraliserad information mer användbar på nationell nivå — utan att undergräva lokal auktoritet.
För infrastrukturteam demonstrerar det också en bredare poäng: AI-experiment behöver inte kompromissa efterlevnad eller kontroll för att vara värdefulla. Läs mer om mina andra AI- och fintech-projekt eller kontakta mig för diskussion om liknande lösningar.